Demonstrating Benford's Law with Google
Crazy math shit to freak you out, and swear words to hold your attention
Introduction
Let's face it, math isn't too cool. In fact, it usually sucks. Big time. But occasionally there's some aspect of mathematics interesting enough to evoke a non-sarcastic "hey, no shit" or if you're lucky maybe even a "noooo fucking way." This is true of Benford's Law. But more on that later.
Benford's Law Introduced
Suppose you went around writing down every possible number you saw - dollar amounts from ATM receipts, random statistics about annual crop yields from the almanac, page numbers of the book you're reading - it doesn't matter the context as long as you gather as many numbers from as many different random sources as possible. You may be asking yourself "Why on Earth anyone would want to do such a thing?" Good question. You're smart! The answer has to do with Benford's Law. So buckle up.
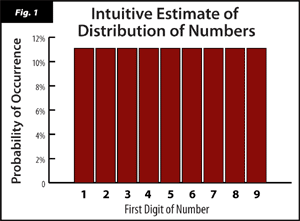 So now you've got this list of hundreds, maybe thousands, of numbers. Now imagine each number is on its own index card inside of a grab bag. So pick a card, any card. Wouldn't you think that your odds of finding a number starting with 1 would be the same as finding a number starting with 9? Or 3? Or 7? (See Figure 1) After all, you gathered as many different numbers from as many different locations as possible, so they should all be evenly distributed, right? Wrong!!! Here comes Benford's Law, bitch!
So now you've got this list of hundreds, maybe thousands, of numbers. Now imagine each number is on its own index card inside of a grab bag. So pick a card, any card. Wouldn't you think that your odds of finding a number starting with 1 would be the same as finding a number starting with 9? Or 3? Or 7? (See Figure 1) After all, you gathered as many different numbers from as many different locations as possible, so they should all be evenly distributed, right? Wrong!!! Here comes Benford's Law, bitch!
Benford's Law Explained
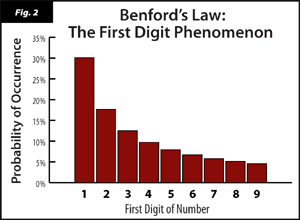
Benford's law says that the odds of obtaining 1 as the first digit of a number are much higher than obtaining any other digit. (See Figure 2) And nobody can really explain why! Creeeepy. But the coolest thing is that the broader the sampling of numbers, the more accurately they conform to Benford's law. For example, if you only examined the numbers in a New York City phone book, it wouldn't fit with Benford's law because your data would favor 2s and 7s (because of the popular area codes 212 and 718). But mix a phone book's numbers with an almanac's numbers with an encyclopedia's numbers and without a doubt you'll start seeing a "Benfordian" distribution. Didn't I tell you this shit'd freak you out?
But the most important part of Benford's law (and partially why it's so fascinating) is that it only works with numbers observed and gathered from the real world. So if you were to randomly generate a list of numbers with a computer, or by simply making them up, their first digits would most likely be evenly distributed from 1-9 and NOT in accordance with Benford's law. (See Figure 1 again). For this reason, Benford's law is used by the IRS to spot defrauders who make up phony numbers, because if the numbers don't follow Benford's law, they weren't from real transactions.
My Experiment
Fascinated by all this, I decided to test it for myself. Rather than spend years gathering numbers from all over the world, I decided to turn to Google - arguably the broadest source of data in existence. Seeing how many results Google finds for a number is a surefire way to judge how many times that number appears in the real world. With a little help from macscripter.net I was able to write a program that Googled a list of numbers almost instantly. So I generated a few lists of random numbers* and fed them into Google. When I looked at the results, sure enough, the numbers that started with 1 showed up the most frequently, followed by 2, then 3 and so on, in a near-perfect example of Benford's law. Holy fuck!!! (Compare Figures 2 and 4)
As expected, 1,000 Google searches is much more in accordance with Benford's law than 100 searches. (Compare Figures 3 and 4) I would have tried 10,000 searches, but Google's "acceptable use policy" forbids any automated searching, so I didn't want to risk it that much. But at least I got to break the law, which made me feel a little less geeky about doing a math experiment. But the cursing helps too.
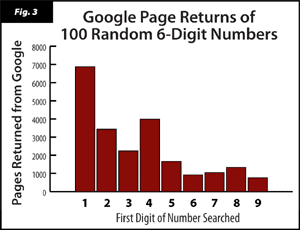
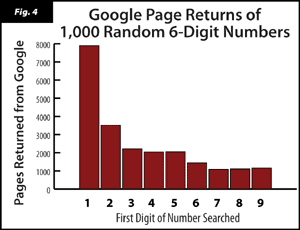
*Why 6-Digit numbers?
Originally I wanted to use numbers of all sizes to plug into Google but then I realized that age, area codes, dates of years, and zip codes would dominate the numbers with 2, 3, 4, and 5 digits respectively. Especially dates... almost every page on the internet has a date on the bottom and it would have severely skewed the data. So with 6 digit numbers, there's no common search result (at least that I've thought of yet) that would be constantly clouding the data.
Is This a Joke?
No. If you read the whole thing you wouldn't have to ask this.
Why did I do this?
Because I was curious. And I don't have cable.
Is that it? Is this the end?
Yeah, no more math. My hands need some serious washing and there's the light switch that needs to be turned on and off 300 times.
UPDATE - 7/3/06
A request for a similar, albeit larger, experient has been posted on the following page:
http://sigfpe.blogspot.com/2006/01/biggest-test-of-benfords-law.html
And below are recent comments from my blog...
Schmidty wrote...
No one knows why? The reason is, I think, people tend to prefer sequential numbers to those of the random persuasion. You may be recording numbers randomly from various sources, but chances are the set of numbers from whence came your "random" number was sequential (serial number, street address, page number, volume, issue, year, etc.). As a group of sequential numbers increases in order of magnitude, the odds that any given number in that set will begin with "1" increases as well. If I have 1,895 pairs of x-ray glasses numbered sequentially from 1 to 1,895, then there are 1,007 pairs whose number start with "1"... more than half.
If I double production, then there are 1,111 pair that begin with "1" and the same amount for "2". "3" weighs in at 902 pairs and "4-9" have 111 each.
In addition, people tend to prefer all of their sequential numbers to have the same number of digits and they don't like leading "0"s. I think this may be for database consistency, but I'm not a DBA so what do I know.
So if I'm Michael Dell and I know that I'm going to sell at least 2,000,000 of a certain model workstation, but no more than 6,000,000, I will begin numbering at 1,000,000; all my workstations will have 7 digits and none will have leading zeros... and the first million will ALL begin with "1". (I know this is a bad example because DELL ID tags are alpha-numeric, but I happen to be ordering computers today so...)
Am I making sense? There are more numbers out there that start with "1" because humans need consistency and order. The rest is just math.
...and Keith wrote...
I think Schmidty is right - moreso with the "1,895 pairs of x-ray
glasses" (maybe that explains why he stares at me all the time these days) than the "people-prefer sequential". Although i agree that's a factor. I enjoy the time of day 12:34 (especially on a clock with seconds at 12:34:56) and because it sticks in my memory like no other time, i forget the rest of the times i check the time, and recall that time of day. Consequently - it seems i happen to check time more frequently at 12:34.
Another "irrandomiser" would BE times of day. Way more 1-starters.
Military time - at first i thought would be equally 1s and 2s. (But enough toilet humour.) But when i gave it some more thought: military times of day would still be heavier on 1s because they stop at 23:59 - and they run through the teens. Butt-loads of 2s though.
Great site. Thanks for the brain scratchings!